信不信這5大MySQL優(yōu)化指南,你一定用得上!
2023-01-06 加入收藏

面試官如果問你:你會從哪些維度進行MySQL性能優(yōu)化?你會怎么回答?
所謂的性能優(yōu)化,一般針對的是MySQL查詢的優(yōu)化。既然是優(yōu)化查詢,我們自然要先知道查詢操作要經(jīng)過哪些環(huán)節(jié),然后思考可以在哪些環(huán)節(jié)進行優(yōu)化。
我之前寫過一條SQL查詢語句是如何執(zhí)行的?,感興趣的朋友可以閱讀一下,我用其中的一張圖展示查詢操作需要經(jīng)歷的基本環(huán)節(jié)。
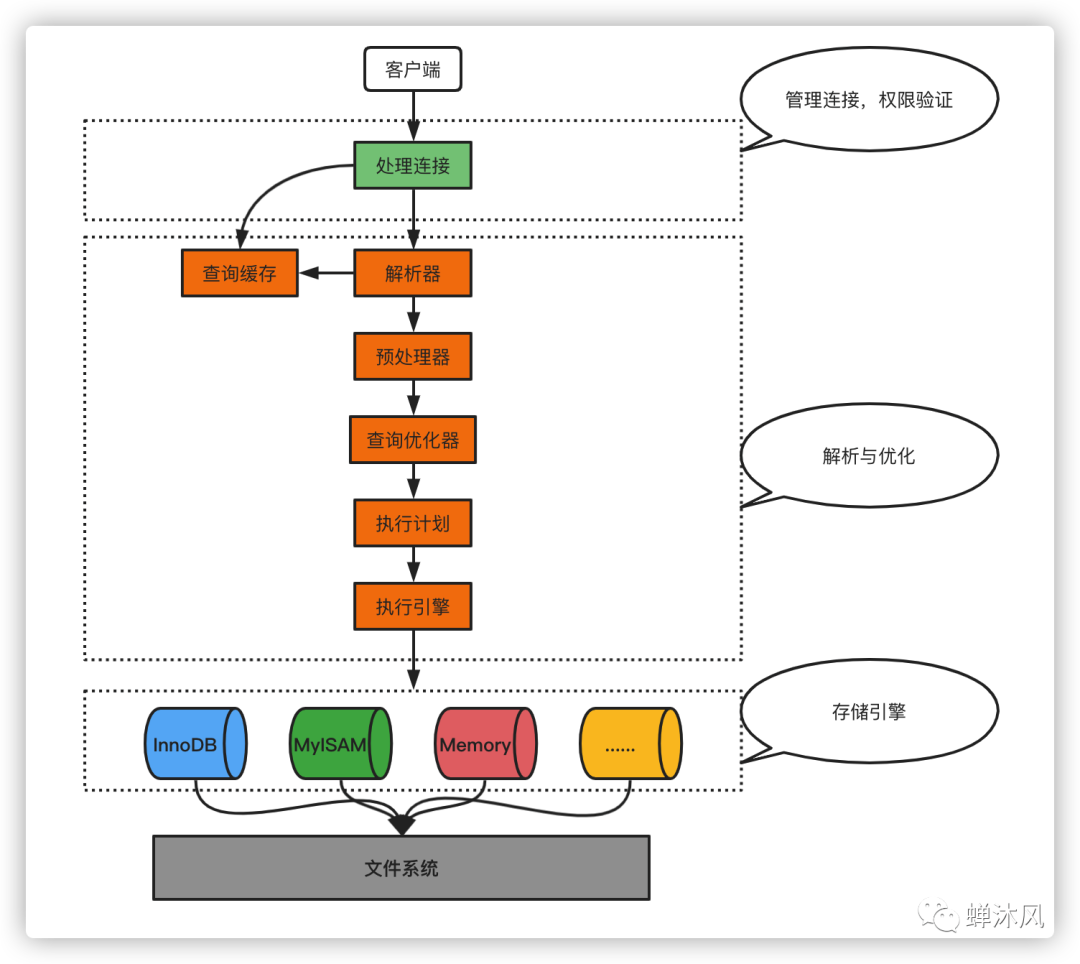
SQL查詢的環(huán)節(jié)
下面從5個角度介紹一下MySQL優(yōu)化的一些策略。
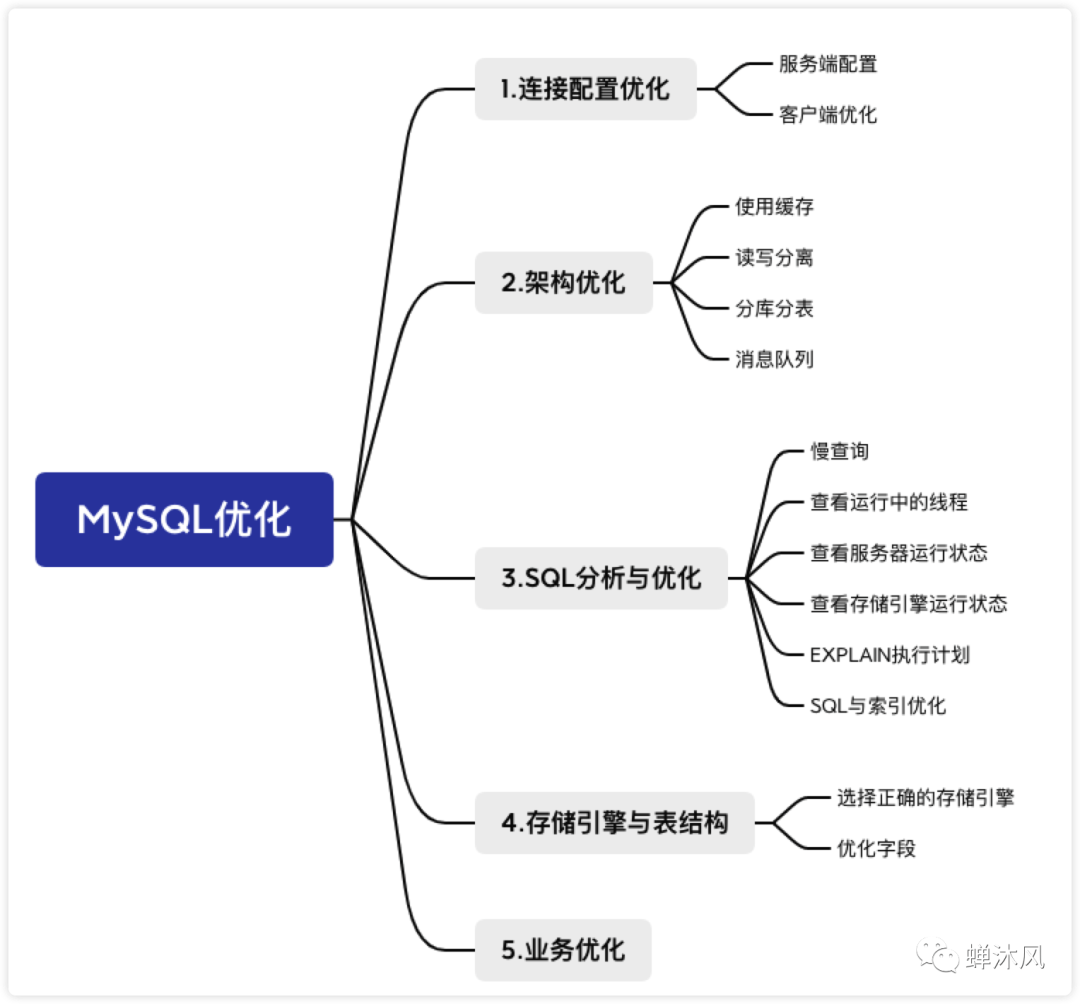
一、連接配置優(yōu)化
處理連接是MySQL客戶端和MySQL服務端親熱的第一步,第一步都邁不好,也就別談后來的故事了。
既然連接是雙方的事情,我們自然從服務端和客戶端兩個方面來進行優(yōu)化嘍。
1、服務端配置
服務端需要做的就是盡可能地多接受客戶端的連接,或許你遇到過error 1040: Too many connections的錯誤?就是服務端的胸懷不夠寬廣導致的,格局太小!

我們可以從兩個方面解決連接數(shù)不夠的問題:
增加可用連接數(shù),修改環(huán)境變量max_connections,默認情況下服務端的最大連接數(shù)為151個;
mysql> show variables like 'max_connections';+-----------------+-------+| Variable_name | Value |+-----------------+-------+| max_connections | 151 |+-----------------+-------+1 row in set (0.01 sec)
及時釋放不活動的連接,系統(tǒng)默認的客戶端超時時間是28800秒(8小時),我們可以把這個值調小一點。
mysql> show variables like 'wait_timeout';+---------------+-------+| Variable_name | Value |+---------------+-------+| wait_timeout | 28800 |+---------------+-------+1 row in set (0.01 sec)
MySQL有非常多的配置參數(shù),并且大部分參數(shù)都提供了默認值,默認值是MySQL作者經(jīng)過精心設計的,完全可以滿足大部分情況的需求,不建議在不清楚參數(shù)含義的情況下貿(mào)然修改。
2、客戶端優(yōu)化
客戶端能做的就是盡量減少和服務端建立連接的次數(shù),已經(jīng)建立的連接能湊合用就湊合用,別每次執(zhí)行個SQL語句都創(chuàng)建個新連接,服務端和客戶端的資源都吃不消啊。
解決的方案就是使用連接池來復用連接。
常見的數(shù)據(jù)庫連接池有DBCP、C3P0、阿里的Druid、Hikari,前兩者用得很少了,后兩者目前如日中天。
但是需要注意的是連接池并不是越大越好,比如Druid的默認最大連接池大小是8,Hikari默認最大連接池大小是10,盲目地加大連接池的大小,系統(tǒng)執(zhí)行效率反而有可能降低。為什么?
對于每一個連接,服務端會創(chuàng)建一個單獨的線程去處理,連接數(shù)越多,服務端創(chuàng)建的線程自然也就越多。而線程數(shù)超過CPU個數(shù)的情況下,CPU勢必要通過分配時間片的方式進行線程的上下文切換,頻繁的上下文切換會造成很大的性能開銷。
Hikari官方給出了一個PostgreSQL數(shù)據(jù)庫連接池大小的建議值公式,CPU核心數(shù)*2+1。假設服務器的CPU核心數(shù)是4,把連接池設置成9就可以了。這種公式在一定程度上對其他數(shù)據(jù)庫也是適用的,大家面試的時候可以吹一吹。
二、架構優(yōu)化
1、使用緩存
系統(tǒng)中難免會出現(xiàn)一些比較慢的查詢,這些查詢要么是數(shù)據(jù)量大,要么是查詢復雜(關聯(lián)的表多或者是計算復雜),使得查詢會長時間占用連接。
如果這種數(shù)據(jù)的實效性不是特別強(不是每時每刻都會變化,例如每日報表),我們可以把此類數(shù)據(jù)放入緩存系統(tǒng)中,在數(shù)據(jù)的緩存有效期內,直接從緩存系統(tǒng)中獲取數(shù)據(jù),這樣就可以減輕數(shù)據(jù)庫的壓力并提升查詢效率。
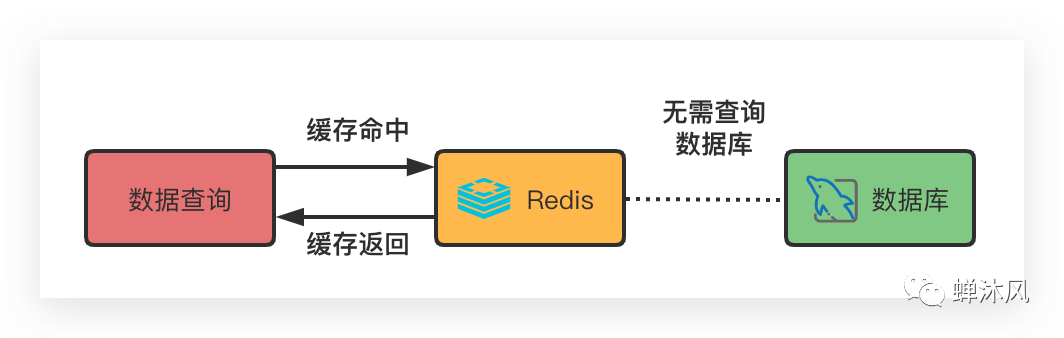
緩存的使用
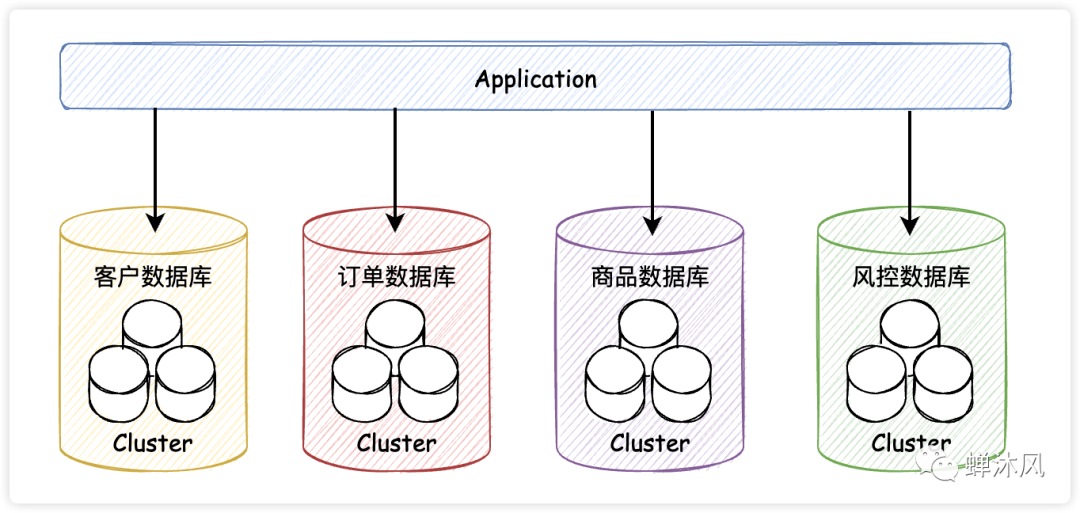
2、讀寫分離(集群、主從復制)
項目的初期,數(shù)據(jù)庫通常都是運行在一臺服務器上的,用戶的所有讀寫請求會直接作用到這臺數(shù)據(jù)庫服務器,單臺服務器承擔的并發(fā)量畢竟是有限的。
針對這個問題,我們可以同時使用多臺數(shù)據(jù)庫服務器,將其中一臺設置為為小組長,稱之為master節(jié)點,其余節(jié)點作為組員,叫做slave。用戶寫數(shù)據(jù)只往master節(jié)點寫,而讀的請求分攤到各個slave節(jié)點上。這個方案叫做讀寫分離。給組長加上組員組成的小團體起個名字,叫集群。
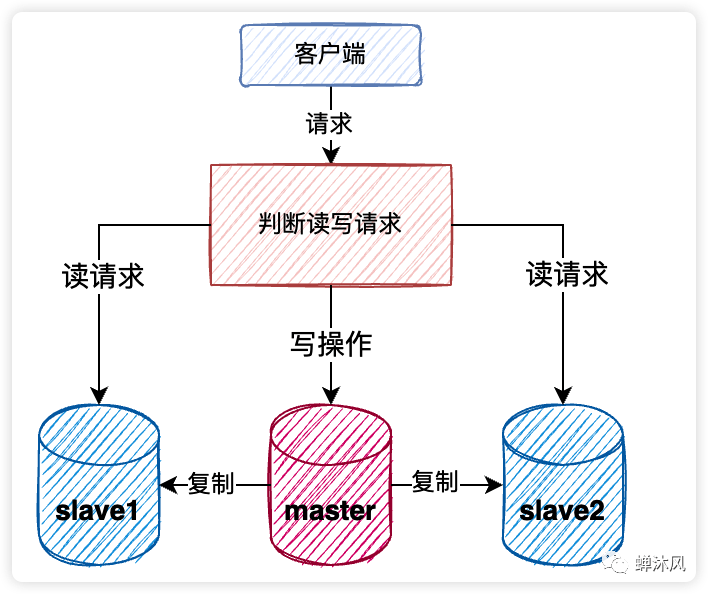
這就是集群
很多開發(fā)者不滿master-slave這種具有侵犯性的詞匯(因為他們認為會聯(lián)想到種族歧視、黑人奴隸等),所以發(fā)起了一項更名運動。
受此影響MySQL也會逐漸停用master、slave等術語,轉而用source和replica替代,大家碰到的時候明白即可。
使用集群必然面臨一個問題,就是多個節(jié)點之間怎么保持數(shù)據(jù)的一致性。畢竟寫請求只往master節(jié)點上發(fā)送了,只有master節(jié)點的數(shù)據(jù)是最新數(shù)據(jù),怎么把對master節(jié)點的寫操作也同步到各個slave節(jié)點上呢?
主從復制技術來了!
binlog是實現(xiàn)MySQL主從復制功能的核心組件。master節(jié)點會將所有的寫操作記錄到binlog中,slave節(jié)點會有專門的I/O線程讀取master節(jié)點的binlog,將寫操作同步到當前所在的slave節(jié)點。
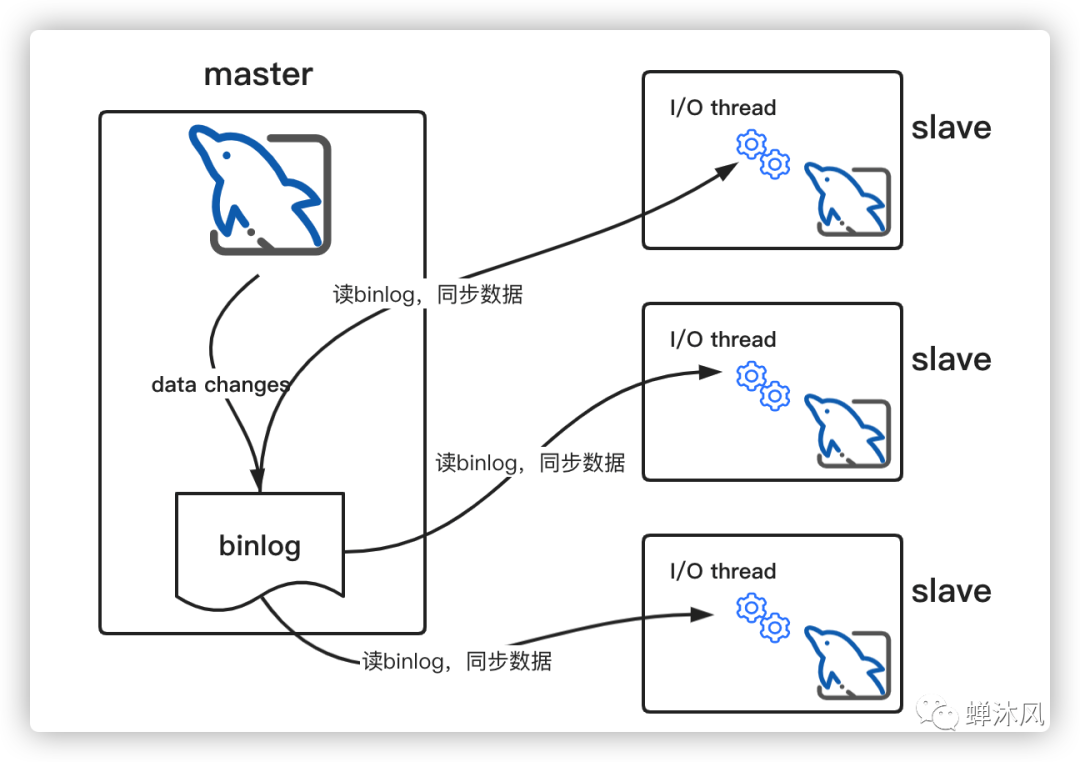
主從復制
這種集群的架構對減輕主數(shù)據(jù)庫服務器的壓力有非常好的效果,但是隨著業(yè)務數(shù)據(jù)越來越多,如果某張表的數(shù)據(jù)量急劇增加,單表的查詢性能就會大幅下降,而這個問題是讀寫分離也無法解決的,畢竟所有節(jié)點存放的是一模一樣的數(shù)據(jù)啊,單表查詢性能差,說的自然也是所有節(jié)點性能都差。
這時我們可以把單個節(jié)點的數(shù)據(jù)分散到多個節(jié)點上進行存儲,這就是分庫分表。
3、分庫分表
分庫分表中的節(jié)點的含義比較寬泛,要是把數(shù)據(jù)庫作為節(jié)點,那就是分庫;如果把單張表作為節(jié)點,那就是分表。
大家都知道分庫分表分成垂直分庫、垂直分表、水平分庫和水平分表,但是每次都記不住這些概念,我就給大家詳細說一說,幫助大家理解。
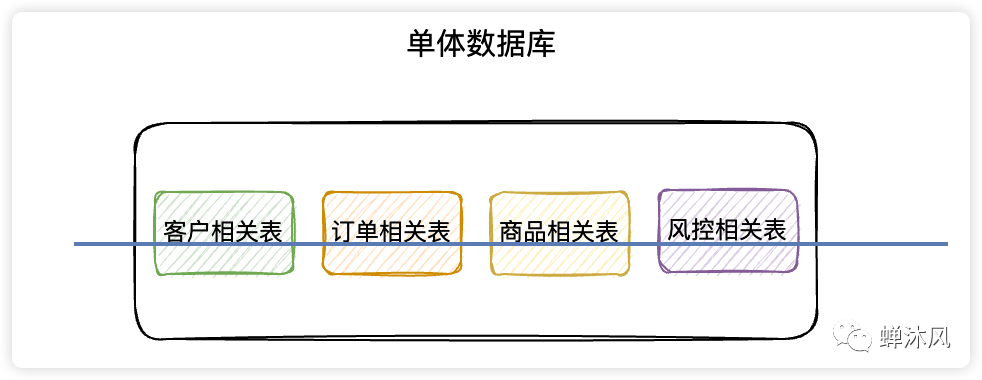
1)垂直分庫
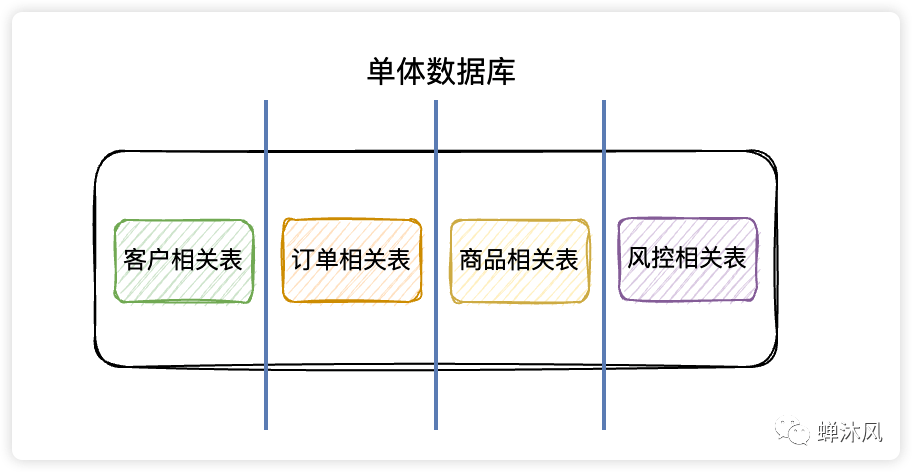
垂直分庫
在單體數(shù)據(jù)庫的基礎上垂直切幾刀,按照業(yè)務邏輯拆分成不同的數(shù)據(jù)庫,這就是垂直分庫啦。
垂直分庫
2)垂直分表
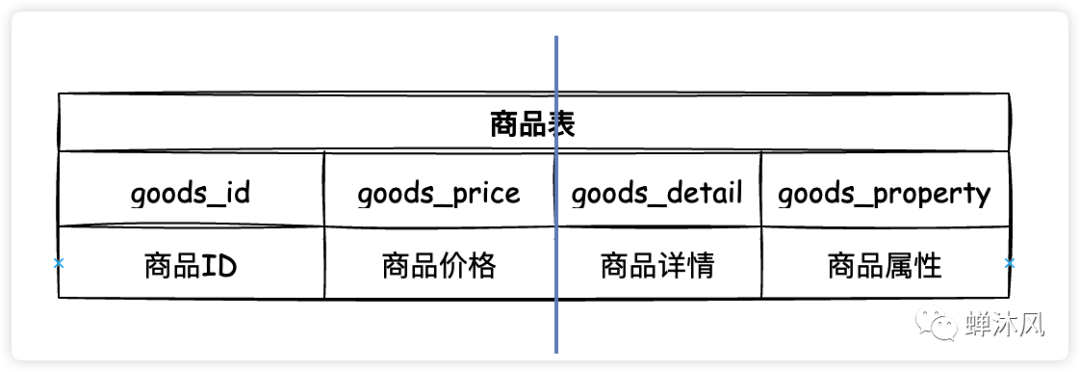
垂直分表
垂直分表就是在單表的基礎上垂直切一刀(或幾刀),將一個表的多個字短拆成若干個小表,這種操作需要根據(jù)具體業(yè)務來進行判斷,通常會把經(jīng)常使用的字段(熱字段)分成一個表,不經(jīng)常使用或者不立即使用的字段(冷字段)分成一個表,提升查詢速度。
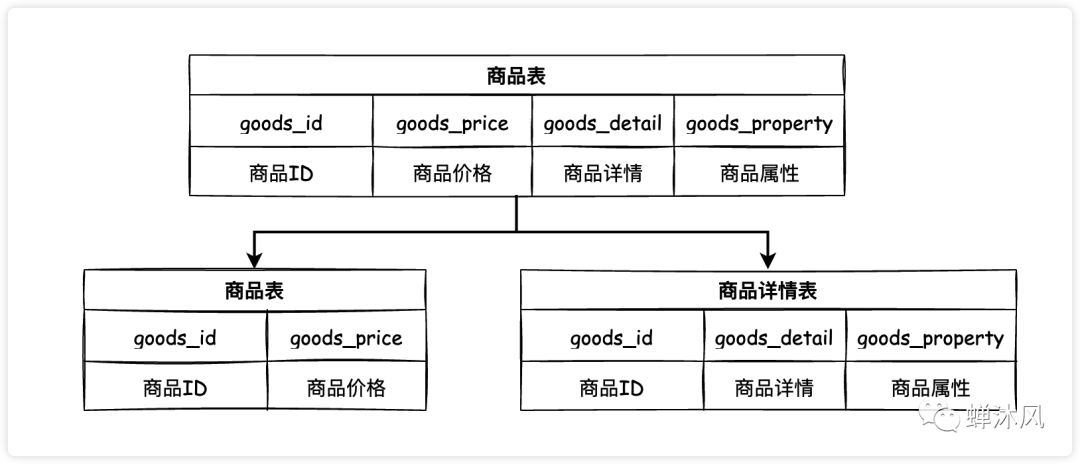
垂直分表
拿上圖舉例:通常情況下商品的詳情信息都比較長,而且查看商品列表時往往不需要立即展示商品詳情(一般都是點擊詳情按鈕才會進行顯示),而是會將商品更重要的信息(價格等)展示出來,按照這個業(yè)務邏輯,我們將原來的商品表做了垂直分表。
3)水平分表
把單張表的數(shù)據(jù)按照一定的規(guī)則(行話叫分片規(guī)則)保存到多個數(shù)據(jù)表上,橫著給數(shù)據(jù)表來一刀(或幾刀),就是水平分表了。
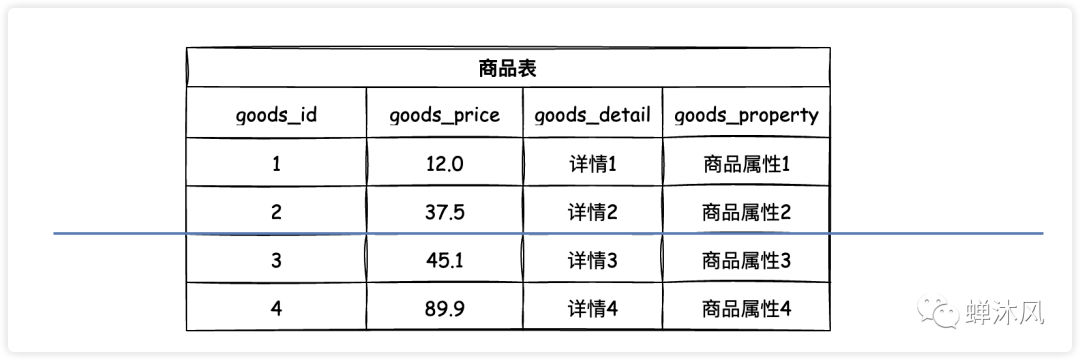
水平分表

水平分表
4)水平分庫
水平分庫就是對單個數(shù)據(jù)庫水平切一刀,往往伴隨著水平分表。
水平分庫

水平分庫
5)總結
水平分,主要是為了解決存儲的瓶頸;垂直分,主要是為了減輕并發(fā)壓力。
4、消息隊列削峰
通常情況下,用戶的請求會直接訪問數(shù)據(jù)庫,如果同一時刻在線用戶數(shù)量非常龐大,極有可能壓垮數(shù)據(jù)庫(參考明星出軌或公布戀情時微博的狀態(tài))。
這種情況下可以通過使用消息隊列降低數(shù)據(jù)庫的壓力,不管同時有多少個用戶請求,先存入消息隊列,然后系統(tǒng)有條不紊地從消息隊列中消費請求。
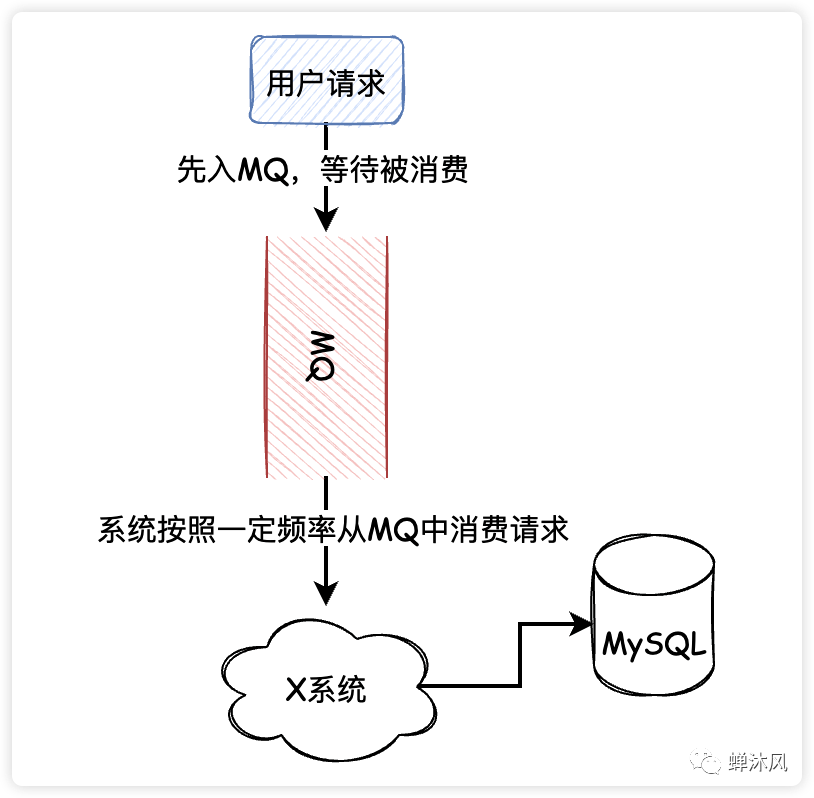
隊列削峰
三、優(yōu)化器——SQL分析與優(yōu)化
處理完連接、優(yōu)化完緩存等架構的事情,SQL查詢語句來到了解析器和優(yōu)化器的地盤了。在這一步如果出了任何問題,那就只能是SQL語句的問題了。
只要你的語法不出問題,解析器就不會有問題。此外,為了防止你寫的SQL運行效率低,優(yōu)化器會自動做一些優(yōu)化,但如果實在是太爛,優(yōu)化器也救不了你了,只能眼睜睜地看著你的SQL查詢淪為慢查詢。
1、慢查詢
慢查詢就是執(zhí)行得很慢的查詢(這句話說得跟廢話似的。。。),只有知道MySQL中有哪些慢查詢我們才能針對性地進行優(yōu)化。
因為開啟慢查詢日志是有性能代價的,因此MySQL默認是關閉慢查詢日志功能,使用以下命令查看當前慢查詢狀態(tài)。
mysql> show variables like 'slow_query%';+---------------------+--------------------------------------+| Variable_name | Value |+---------------------+--------------------------------------+| slow_query_log | OFF || slow_query_log_file | /var/lib/mysql/9e74f9251f6c-slow.log |+---------------------+--------------------------------------+2 rows in set (0.00 sec)
slow_query_log表示當前慢查詢日志是否開啟,slow_query_log_file表示慢查詢日志的保存位置。
除了上面兩個變量,我們還需要確定“慢”的指標是什么,即執(zhí)行超過多長時間才算是慢查詢,默認是10S,如果改成0的話就是記錄所有的SQL。
mysql> show variables like '%long_query%';+-----------------+-----------+| Variable_name | Value |+-----------------+-----------+| long_query_time | 10.000000 |+-----------------+-----------+1 row in set (0.00 sec)
1)打開慢日志
有兩種打開慢日志的方式。
修改配置文件my.cnf
此種修改方式系統(tǒng)重啟后依然有效。
# 是否開啟慢查詢日志slow_query_log=ON# long_query_time=2slow_query_log_file=/var/lib/mysql/slow.log
動態(tài)修改參數(shù)(重啟后失效)
mysql> set @@global.slow_query_log=1;Query OK, 0 rows affected (0.06 sec)mysql> set @@global.long_query_time=2;Query OK, 0 rows affected (0.00 sec)
2)慢日志分析
MySQL不僅為我們保存了慢日志文件,還為我們提供了慢日志查詢的工具mysqldumpslow,為了演示這個工具,我們先構造一條慢查詢:
mysql> SELECT sleep(5);
然后我們查詢用時最多的1條慢查詢:
[root@iZ2zejfuakcnnq2pgqyzowZ ~]# mysqldumpslow -s t -t 1 -g 'select' /var/lib/mysql/9e74f9251f6c-slow.logReading mysql slow query log from /var/lib/mysql/9e74f9251f6c-slow.logCount: 1 Time=10.00s (10s) Lock=0.00s (0s) Rows=1.0 (1), root[root]@localhost SELECT sleep(N)
其中,
Count:表示這個SQL執(zhí)行的次數(shù)。
Time:表示執(zhí)行的時間,括號中的是累積時間。
Locks:表示鎖定的時間,括號中的是累積時間。
Rows:表示返回的記錄數(shù),括號中的是累積數(shù)。
更多關于mysqldumpslow的使用方式,可以查閱官方文檔,或者執(zhí)行mysqldumpslow --help尋求幫助。
2、查看運行中的線程
我們可以運行show full processlist查看MySQL中運行的所有線程,查看其狀態(tài)和運行時間,找到不順眼的,直接kill。
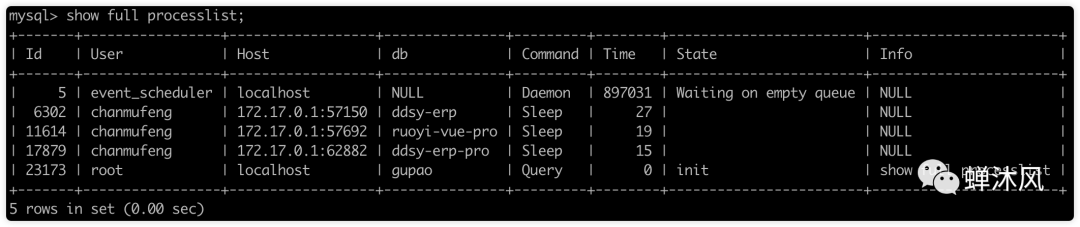
其中,
Id:線程的唯一標志,可以使用Id殺死指定線程。
User:啟動這個線程的用戶,普通賬戶只能查看自己的線程。
Host:哪個ip和端口發(fā)起的連接。
db:線程操作的數(shù)據(jù)庫。
Command:線程的命令。
Time:操作持續(xù)時間,單位秒。
State:線程的狀態(tài)。
Info:SQL語句的前100個字符。
3、查看服務器運行狀態(tài)
使用SHOW STATUS查看MySQL服務器的運行狀態(tài),有session和global兩種作用域,一般使用like+通配符進行過濾。
-- 查看select的次數(shù)mysql> SHOW GLOBAL STATUS LIKE 'com_select';+---------------+--------+| Variable_name | Value |+---------------+--------+| Com_select | 168241 |+---------------+--------+1 row in set (0.05 sec)
4、查看存儲引擎運行信息
SHOW ENGINE用來展示存儲引擎的當前運行信息,包括事務持有的表鎖、行鎖信息;事務的鎖等待情況;線程信號量等待;文件IO請求;Buffer pool統(tǒng)計信息等等數(shù)據(jù)。
例如:
SHOW ENGINE INNODB STATUS;
上面這條語句可以展示innodb存儲引擎的當前運行的各種信息,大家可以據(jù)此找到MySQL當前的問題,限于篇幅不在此意義說明其中信息的含義,大家只要知道MySQL提供了這樣一個監(jiān)控工具就行了,等到需要的時候再來用就好。
5、EXPLAIN執(zhí)行計劃
通過慢查詢日志我們可以知道哪些SQL語句執(zhí)行慢了,可是為什么慢?慢在哪里呢?
MySQL提供了一個執(zhí)行計劃的查詢命令EXPLAIN,通過此命令我們可以查看SQL執(zhí)行的計劃,所謂執(zhí)行計劃就是:優(yōu)化器會不會優(yōu)化我們自己書寫的SQL語句(比如外連接改內連接查詢,子查詢優(yōu)化為連接查詢...)、優(yōu)化器針對此條SQL的執(zhí)行對哪些索引進行了成本估算,并最終決定采用哪個索引(或者最終選擇不用索引,而是全表掃描)、優(yōu)化器對單表執(zhí)行的策略是什么,等等等等。
EXPLAIN在MySQL5.6.3之后也可以針對UPDATE、DELETE和INSERT語句進行分析,但是通常情況下我們還是用在SELECT查詢上。
這篇文章主要是從宏觀上多個角度介紹MySQL的優(yōu)化策略,因此這里不詳細說明EXPLAIN的細節(jié)。
6、SQL與索引優(yōu)化
1)SQL優(yōu)化
SQL優(yōu)化指的是SQL本身語法沒有問題,但是有實現(xiàn)相同目的的更好的寫法。比如:
使用小表驅動大表;用join改寫子查詢;or改成union;
連接查詢中,盡量減少驅動表的扇出(記錄數(shù)),訪問被驅動表的成本要盡量低,盡量在被驅動表的連接列上建立索引,降低訪問成本;被驅動表的連接列最好是該表的主鍵或者是唯一二級索引列,這樣被驅動表的成本會降到更低;
大偏移量的limit,先過濾再排序。
針對最后一條舉個簡單的例子,下面兩條語句能實現(xiàn)同樣的目的,但是第二條的執(zhí)行效率比第一條執(zhí)行效率要高得多(存儲引擎使用的是InnoDB),大家感受一下:
-- 1. 大偏移量的查詢mysql> SELECT * FROM user_innodb LIMIT 9000000,10;Empty set (8.18 sec)-- 2.先過濾ID(因為ID使用的是索引),再limitmysql> SELECT * FROM user_innodb WHERE id > 9000000 LIMIT 10;Empty set (0.02 sec)
2)索引優(yōu)化
為慢查詢創(chuàng)建適當?shù)乃饕莻€非常常見并且非常有效的方法,但是索引是否會被高效使用又是另一門學問了。
四、存儲引擎與表結構
1、選擇存儲引擎
一般情況下,我們會選擇MySQL默認的存儲引擎存儲引擎InnoDB,但是當對數(shù)據(jù)庫性能要求精益求精的時候,存儲引擎的選擇也成為一個關鍵的影響因素。
建議根據(jù)不同的業(yè)務選擇不同的存儲引擎,例如:
查詢操作、插入操作多的業(yè)務表,推薦使用MyISAM;
臨時表使用Memory;
并發(fā)數(shù)量大、更新多的業(yè)務選擇使用InnoDB;
不知道選啥直接默認。
2、優(yōu)化字段
字段優(yōu)化的最終原則是:使用可以正確存儲數(shù)據(jù)的最小的數(shù)據(jù)類型。
1)整數(shù)類型
MySQL提供了6種整數(shù)類型,分別是:
tinyint
smallint
mediumint
int
integer
bigint
不同的存儲類型的最大存儲范圍不同,占用的存儲的空間自然也不同。
例如,是否被刪除的標識,建議選用tinyint,而不是bigint。
2)字符類型
你是不是直接把所有字符串的字段都設置為varchar格式了?甚至怕不夠,還會直接設置成varchar(1024)的長度?
如果不確定字段的長度,肯定是要選擇varchar,但是varchar需要額外的空間來記錄該字段目前占用的長度;因此如果字段的長度是固定的,盡量選用char,這會給你節(jié)約不少的內存空間。
3)非空
非空字段盡量設置成NOT NULL,并提供默認值,或者使用特殊值代替NULL。
因為NULL類型的存儲和優(yōu)化都會存在性能不佳的問題,具體原因在這里就不展開了。
4)不要用外鍵、觸發(fā)器和視圖功能
這也是「阿里巴巴開發(fā)手冊」中提到的原則。原因有三個:
降低了可讀性,檢查代碼的同時還得查看數(shù)據(jù)庫的代碼;
把計算的工作交給程序,數(shù)據(jù)庫只做好存儲的工作,并把這件事情做好;
數(shù)據(jù)的完整性校驗的工作應該由開發(fā)者完成,而不是依賴于外鍵,一旦用了外鍵,你會發(fā)現(xiàn)測試的時候隨便刪點垃圾數(shù)據(jù)都變得異常艱難。
5)圖片、音頻、視頻存儲
不要直接存儲大文件,而是要存儲大文件的訪問地址。
6)大字段拆分和數(shù)據(jù)冗余
大字段拆分其實就是前面說過的垂直分表,把不常用的字段或者數(shù)據(jù)量較大的字段拆分出去,避免列數(shù)過多和數(shù)據(jù)量過大,尤其是習慣編寫SELECT *的情況下,列數(shù)多和數(shù)據(jù)量大導致的問題會被嚴重放大!
字段冗余原則上不符合數(shù)據(jù)庫設計范式,但是卻非常有利于快速檢索。比如,合同表中存儲客戶id的同時可以冗余存儲客戶姓名,這樣查詢時就不需要再根據(jù)客戶id獲取用戶姓名了。因此針對業(yè)務邏輯適當做一定程度的冗余也是一種比較好的優(yōu)化技巧。
五、業(yè)務優(yōu)化
嚴格來說,業(yè)務方面的優(yōu)化已經(jīng)不算是MySQL調優(yōu)的手段了,但是業(yè)務的優(yōu)化卻能非常有效地減輕數(shù)據(jù)庫訪問壓力,這方面一個典型例子就是淘寶,下面舉幾個簡單例子給大家提供一下思路:
以往都是雙11當晚開始買買買的模式,最近幾年雙11的預售戰(zhàn)線越拉越長,提前半個多月就開始了,而且各種定金紅包模式層出不窮,這種方式叫做預售分流。這樣做可以分流客戶的服務請求,不必等到雙十一的凌晨一股腦地集體下單;
雙十一的凌晨你或許想查詢當天之外的訂單,但是卻查詢失敗;甚至支付寶里的小雞的口糧都被延遲發(fā)放了,這是一種降級策略,集結不重要的服務的計算資源,用來保證當前最核心的業(yè)務;
雙十一的時候支付寶極力推薦使用花唄支付,而不是銀行卡支付,雖然一部分考量是提高軟件粘性,但是另一方面,使用余額寶實際使用的阿里內部服務器,訪問速度快,而使用銀行卡,需要調用銀行接口,相比之下操作要慢了許多。